
The arithmetic mean has a number of properties that more fully reveal its essence and simplify the calculation:
1. The product of the average and the sum of the frequencies is always equal to the sum of the products of the variant and the frequencies, i.e.
2. The arithmetic mean of the sum of the varying values is equal to the sum of the arithmetic means of these values:
3. The algebraic sum of the deviations of the individual values of the attribute from the average is zero:
![]()
4. The sum of the squared deviations of the options from the mean is less than the sum of the squared deviations from any other arbitrary value, i.e.:
5. If all variants of the series are reduced or increased by the same number, then the average will decrease by the same number:

6. If all variants of the series are reduced or increased by a factor, then the average will also decrease or increase by a factor:

7. If all frequencies (weights) are increased or decreased by a factor, then the arithmetic mean will not change:

This method is based on the use of the mathematical properties of the arithmetic mean. In this case, the average value is calculated by the formula: , where i is the value of an equal interval or any constant number not equal to 0; m 1 - moment of the first order, which is calculated by the formula:  ; A is any constant number.
; A is any constant number.
18 SIMPLE HARMONIC AVERAGE AND WEIGHTED.
Average harmonic is used in cases where the frequency is unknown (f i), and the volume of the studied trait is known (x i *f i =M i).
Using example 2, we determine the average wage in 2001.
In the original information of 2001. there is no data on the number of employees, but it is not difficult to calculate it as the ratio of the wage bill to the average wage.
Then  2769.4 rubles, i.e. average salary in 2001 -2769.4 rubles.
2769.4 rubles, i.e. average salary in 2001 -2769.4 rubles.
In this case, the harmonic mean is used: ,
where M i is the wage fund in a separate workshop; x i - salary in a separate shop.
Therefore, the harmonic mean is used when one of the factors is unknown, but the product "M" is known.
The harmonic mean is used to calculate the average labor productivity, the average percentage of compliance with the norms, the average salary, etc.
If the products of "M" are equal to each other, then the harmonic simple mean is used: , where n is the number of options.
GEOMETRIC AVERAGE AND CHRONOLOGICAL AVERAGE.
The geometric mean is used to analyze the dynamics of phenomena and allows you to determine the average growth rate. When calculating the geometric mean, the individual values of a trait usually represent relative indicators of dynamics, built in the form of chain values, as the ratio of each level of the series to the previous level.
![]() , - chain coefficients of growth;
, - chain coefficients of growth;
n is the number of chain growth factors.
If the initial data is given as of certain dates, then the average level of the attribute is determined by the chronological average formula. If the intervals between dates (moments) are equal, then the average level is determined by the formula of the average chronological simple.
Let's consider its calculation on specific examples.
Example. The following data are available on the balances of household deposits in Russian banks in the first half of 1997 (at the beginning of the month):
The average balance of deposits of the population for the first half of 1997 (according to the formula of the average chronological idle time) amounted to.
Variation range (or range of variation) - is the difference between the maximum and minimum values of the feature:
In our example, the range of variation in shift output of workers is: in the first brigade R=105-95=10 children, in the second brigade R=125-75=50 children. (5 times more). This suggests that the output of the 1st brigade is more “stable”, but the second brigade has more reserves for the growth of output, because. if all workers reach the maximum output for this brigade, it can produce 3 * 125 = 375 parts, and in the 1st brigade only 105 * 3 = 315 parts.
If the extreme values of the attribute are not typical for the population, then quartile or decile ranges are used. The quartile range RQ= Q3-Q1 covers 50% of the population, the first decile range RD1 = D9-D1 covers 80% of the data, the second decile range RD2= D8-D2 covers 60%.
The disadvantage of the variation range indicator is, but that its value does not reflect all the fluctuations of the trait.
The simplest generalizing indicator that reflects all the fluctuations of a trait is mean linear deviation, which is the arithmetic mean of the absolute deviations of individual options from their average value:
,
for grouped data ![]() ,
,
where хi is the value of the attribute in a discrete series or the middle of the interval in the interval distribution.
In the above formulas, the differences in the numerator are taken modulo, otherwise, according to the property of the arithmetic mean, the numerator will always be equal to zero. Therefore, the average linear deviation is rarely used in statistical practice, only in those cases where summing the indicators without taking into account the sign makes economic sense. With its help, for example, the composition of employees, the profitability of production, and foreign trade turnover are analyzed.
Feature variance is the average square of the deviations of the variant from their average value:
simple variance ![]() ,
,
weighted variance  .
.
The formula for calculating the variance can be simplified:
Thus, the variance is equal to the difference between the mean of the squares of the variant and the square of the mean of the variant of the population:  .
.
However, due to the summation of the squared deviations, the variance gives a distorted idea of the deviations, so the average is calculated from it. standard deviation, which shows how much the specific variants of the attribute deviate on average from their average value. Calculated by extracting square root from dispersion:
for ungrouped data  ,
,
for the variation series 
How less value dispersion and standard deviation, the more homogeneous the population, the more reliable (typical) the average value will be.
The mean linear and mean square deviation are named numbers, i.e., they are expressed in units of measurement of the attribute, are identical in content and close in value.
It is recommended to calculate the absolute indicators of variation using tables.
Table 3 - Calculation of the characteristics of variation (on the example of the period of data on the shift output of the work teams)
Number of workers |
The middle of the interval |
Estimated values |
|||||
Total: |
|||||||
Average shift output of workers: ![]()
Average linear deviation: ![]()
Output dispersion: 
The standard deviation of the output of individual workers from the average output:
.
1 Calculation of dispersion by the method of moments
The calculation of variances is associated with cumbersome calculations (especially if the average is expressed as a large number with several decimal places). Calculations can be simplified by using a simplified formula and dispersion properties.
The dispersion has the following properties:
- if all the values of the attribute are reduced or increased by the same value A, then the variance will not decrease from this:
 ,
,
 , then or
, then or 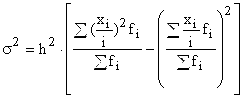
Using the properties of the variance and first reducing all the variants of the population by the value A, and then dividing by the value of the interval h, we obtain a formula for calculating the variance in variational series with equal intervals way of moments: ,
,
where is the dispersion calculated by the method of moments;
h is the value of the interval of the variation series;
– new (transformed) variant values;
A is a constant value, which is used as the middle of the interval with the highest frequency; or the variant with the highest frequency;  is the square of the moment of the first order;
is the square of the moment of the first order;
is a moment of the second order.
Let's calculate the variance by the method of moments based on the data on the shift output of the working team.
Table 4 - Calculation of dispersion by the method of moments
Groups of production workers, pcs. |
Number of workers |
The middle of the interval |
Estimated values |
||
Calculation procedure:


- calculate the variance:
2 Calculation of the variance of an alternative feature
Among the signs studied by statistics, there are those that have only two mutually exclusive meanings. These are alternative signs. They are given two quantitative values, respectively: options 1 and 0. The frequency of options 1, which is denoted by p, is the proportion of units that have this feature. The difference 1-p=q is the frequency of options 0. Thus,
xi |
|
Arithmetic mean of alternative feature ![]() , since p+q=1.
, since p+q=1.
Feature variance
, because 1-p=q
Thus, the variance of an alternative attribute is equal to the product of the proportion of units that have this attribute and the proportion of units that do not have this attribute.
If the values 1 and 0 are equally frequent, i.e. p=q, the variance reaches its maximum pq=0.25.
Variance variable is used in sample surveys, for example, product quality.
3 Intergroup dispersion. Variance addition rule
Dispersion, unlike other characteristics of variation, is an additive quantity. That is, in the aggregate, which is divided into groups according to the factor criterion X , resultant variance y can be decomposed into variance within each group (within group) and variance between groups (between group). Then, along with the study of the variation of the trait throughout the population as a whole, it becomes possible to study the variation in each group, as well as between these groups.
Total variance measures the variation of a trait at over the entire population under the influence of all the factors that caused this variation (deviations). It is equal to the mean square of the deviations of the individual values of the feature at of the overall mean and can be calculated as simple or weighted variance.
Intergroup variance characterizes the variation of the effective feature at, caused by the influence of the sign-factor X underlying the grouping. It characterizes the variation of the group means and is equal to the mean square of the deviations of the group means from the total mean:  ,
,
where is the arithmetic mean of the i-th group;
– number of units in the i-th group (frequency of the i-th group);
is the total mean of the population.
Intragroup variance reflects random variation, i.e., that part of the variation that is caused by the influence of unaccounted for factors and does not depend on the attribute-factor underlying the grouping. It characterizes the variation of individual values relative to group averages, it is equal to the mean square of deviations of individual values of the trait at within a group from the arithmetic mean of this group (group mean) and is calculated as a simple or weighted variance for each group: ![]() or
or ![]() ,
,
where is the number of units in the group.
Based on the intra-group variances for each group, it is possible to determine the overall average of the within-group variances:
.
The relationship between the three variances is called variance addition rules, according to which the total variance is equal to the sum of the intergroup variance and the average of the intragroup variances:
Example. When studying the influence of the tariff category (qualification) of workers on the level of productivity of their labor, the following data were obtained.
Table 5 - Distribution of workers by average hourly output.
№ p/n |
Workers of the 4th category |
Workers of the 5th category |
|||||
Working out |
Working out |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
In this example, the workers are divided into two groups according to the factor X- qualifications, which are characterized by their rank. The effective trait - production - varies both under its influence (intergroup variation) and due to other random factors (intragroup variation). The challenge is to measure these variations using three variances: total, between-group, and within-group. The empirical coefficient of determination shows the proportion of the variation of the resulting feature at under the influence of a factor sign X. The rest of the total variation at caused by changes in other factors.
In the example, the empirical coefficient of determination is: ![]() or 66.7%,
or 66.7%,
This means that 66.7% of the variation in labor productivity of workers is due to differences in qualifications, and 33.3% is due to the influence of other factors.
Empirical correlation relation shows the tightness of the relationship between the grouping and effective features. It is calculated as the square root of the empirical coefficient of determination:
The empirical correlation ratio , as well as , can take values from 0 to 1.
If there is no connection, then =0. In this case, =0, that is, the group means are equal to each other and there is no intergroup variation. This means that the grouping sign - the factor does not affect the formation of the general variation.
If the relationship is functional, then =1. In this case, the variance of the group means is equal to the total variance (), i.e., there is no intragroup variation. This means that the grouping feature completely determines the variation of the resulting feature being studied.
The closer the value of the correlation relation is to one, the closer, closer to the functional dependence, the relationship between the features.
For a qualitative assessment of the closeness of the connection between the signs, the Chaddock relations are used.
In the example ![]() , which indicates a close relationship between the productivity of workers and their qualifications.
, which indicates a close relationship between the productivity of workers and their qualifications.
Where A is a conditional zero equal to the variant with the maximum frequency (the middle of the interval with the maximum frequency), h is the interval step,
Service assignment. Using the online calculator, the average value is calculated using the method of moments. The result of the decision is drawn up in Word format.
Instruction. To obtain a solution, you must fill in the initial data and select the report options for formatting in Word.
Algorithm for finding the average by the method of moments
Example. The costs of working time for a homogeneous technological operation were distributed among the workers as follows:
Required to define average value the cost of working time and the standard deviation by the method of moments; the coefficient of variation; mode and median.Table for calculating indicators.
| Groups | Interval middle, x i | Quantity, fi | x i f i | Cumulative frequency, S | (x-x ) 2 f |
| 5 - 10 | 7.5 | 20 | 150 | 20 | 4600.56 |
| 15 - 20 | 17.5 | 25 | 437.5 | 45 | 667.36 |
| 20 - 25 | 22.5 | 50 | 1125 | 95 | 1.39 |
| 25 - 30 | 27.5 | 30 | 825 | 125 | 700.83 |
| 30 - 35 | 32.5 | 15 | 487.5 | 140 | 1450.42 |
| 35 - 40 | 37.5 | 10 | 375 | 150 | 2200.28 |
| 150 | 3400 | 9620.83 |
Fashion
where x 0 is the beginning of the modal interval; h is the value of the interval; f 2 -frequency corresponding to the modal interval; f 1 - premodal frequency; f 3 - postmodal frequency.
We choose 20 as the beginning of the interval, since it is this interval that accounts for the largest number.
The most common value of the series is 22.78 min.
Median
The median is the interval 20 - 25, because in this interval, the accumulated frequency S is greater than the median number (the first interval is called the median, the accumulated frequency S of which exceeds half of the total sum of frequencies).
Thus, 50% of the population units will be less than 23 min.
.
We find A = 22.5, interval step h = 5.
Mean squared deviations by the method of moments.
| x c | x*i | x * i f i | 2 f i |
| 7.5 | -3 | -60 | 180 |
| 17.5 | -1 | -25 | 25 |
| 22.5 | 0 | 0 | 0 |
| 27.5 | 1 | 30 | 30 |
| 32.5 | 2 | 30 | 60 |
| 37.5 | 3 | 30 | 90 |
| 5 | 385 |
Standard deviation.
min.
The coefficient of variation- a measure of the relative spread of population values: shows what proportion of the average value of this quantity is its average spread.
Because v>30% but v<70%, то вариация умеренная.
Example
To evaluate the distribution series, we find the following indicators:weighted average
![]()
The average value of the studied trait by the method of moments.
where A is a conditional zero equal to the variant with the maximum frequency (the middle of the interval with the maximum frequency), h is the interval step.
4. Even and odd.
In even variational series, the sum of frequencies or the total number of observations is expressed as an even number, in odd variational series, as an odd number.
5. Symmetrical and asymmetrical.
In a symmetrical variation series, all types of averages coincide or are very close (mode, median, arithmetic mean).
Depending on the nature of the phenomena being studied, on the specific tasks and objectives of the statistical study, as well as on the content of the source material, in sanitary statistics the following types of averages are used:
Structural averages (mode, median);
arithmetic mean;
average harmonic;
The geometric mean
medium progressive.
Fashion (M o) - the value of the variable trait, which is more common in the studied population, i.e. option corresponding to the highest frequency. It is found directly by the structure of the variation series, without resorting to any calculations. It is usually a value very close to the arithmetic mean and is very convenient in practice.
Median (M e) - dividing the variation series (ranked, i.e. the values of the option are arranged in ascending or descending order) into two equal halves. The median is calculated using the so-called odd series, which is obtained by successively summing the frequencies. If the sum of the frequencies corresponds to an even number, then the median is conventionally taken as the arithmetic mean of the two average values.
The mode and median are applied in the case of an open population, i.e. when the largest or smallest options do not have an exact quantitative characteristic (for example, under 15 years old, 50 and older, etc.). In this case, the arithmetic mean (parametric characteristics) cannot be calculated.
Average i arithmetic - the most common value. The arithmetic mean is usually denoted by M.
Distinguish between simple arithmetic mean and weighted mean.
simple arithmetic mean calculated:
— in those cases when the totality is represented by a simple list of knowledge of an attribute for each unit;
— if the number of repetitions of each variant cannot be determined;
— if the numbers of repetitions of each variant are close to each other.
The simple arithmetic mean is calculated by the formula:
where V - individual values of the attribute; n is the number of individual values; - sign of summation.
Thus, the simple average is the ratio of the sum of the variant to the number of observations.
Example: determine the average length of stay in bed for 10 patients with pneumonia:
16 days - 1 patient; 17–1; 18–1; 19–1; 20–1; 21–1; 22–1; 23–1; 26–1; 31–1.
bed-day.
Arithmetic weighted average is calculated in cases where the individual values of the characteristic are repeated. It can be calculated in two ways:
1. Directly (arithmetic mean or direct method) according to the formula:
where P is the frequency (number of cases) of observations of each option.
Thus, the weighted arithmetic mean is the ratio of the sum of the products of the variant by the frequency to the number of observations.
2. By calculating deviations from the conditional average (according to the method of moments).
The basis for calculating the weighted arithmetic mean is:
— grouped material according to variants of a quantitative trait;
— all options should be arranged in ascending or descending order of the attribute value (ranked series).
To calculate by the method of moments, the prerequisite is the same size of all intervals.
According to the method of moments, the arithmetic mean is calculated by the formula:
 ,
,
where M o is the conditional average, which is often taken as the value of the feature corresponding to the highest frequency, i.e. which is more often repeated (Mode).
i - interval value.
a - conditional deviation from the conditions of the average, which is a sequential series of numbers (1, 2, etc.) with a + sign for a large conditional average option and with a - (-1, -2, etc.) sign for a option, which are below the average. The conditional deviation from the variant taken as the conditional average is 0.
P - frequencies.
The total number of observations or n.
Example: determine the average height of 8-year-old boys directly (table 1).
Table 1
|
Height in cm |
Boys P |
Central option V |
|
The central variant, the middle of the interval, is defined as the semi-sum of the initial values of two adjacent groups:
![]() ;
; ![]() etc.
etc.
The VP product is obtained by multiplying the central variants by the frequencies ; etc. Then the resulting products are added and get ![]() , which is divided by the number of observations (100) and the weighted arithmetic mean is obtained.
, which is divided by the number of observations (100) and the weighted arithmetic mean is obtained.
![]() cm.
cm.
We will solve the same problem using the method of moments, for which the following table 2 is compiled:
Table 2
|
Height in cm (V) |
Boys P |
||
We take 122 as M o, because out of 100 observations, 33 people had a height of 122 cm. We find the conditional deviations (a) from the conditional average in accordance with the above. Then we obtain the product of conditional deviations by frequencies (aP) and summarize the obtained values (). The result will be 17. Finally, we substitute the data into the formula.
Property 1. The arithmetic mean constant is equal to this constant: at
Property 2. The algebraic sum of the deviations of the individual values of the attribute from the arithmetic mean is zero: ![]() for ungrouped data and
for ungrouped data and ![]() for distribution rows.
for distribution rows.
This property means that the sum of positive deviations is equal to the sum of negative deviations, i.e. all deviations due to random causes cancel each other out.
Property 3. The sum of the squared deviations of the individual values of the attribute from the arithmetic mean is the minimum number: ![]() for ungrouped data and
for ungrouped data and ![]() for distribution rows. This property means that the sum of the squared deviations of the individual values of a trait from the arithmetic mean is always less than the sum of the deviations of the trait's variants from any other value, even if it differs little from the average.
for distribution rows. This property means that the sum of the squared deviations of the individual values of a trait from the arithmetic mean is always less than the sum of the deviations of the trait's variants from any other value, even if it differs little from the average.
The second and third properties of the arithmetic mean are used to check the correctness of the calculation of the average value; when studying the patterns of changes in the levels of a series of dynamics; to find the parameters of the regression equation when studying the correlation between features.
All three first properties express the essential features of the average as a statistical category.
The following properties of the mean are considered computational because they are of some practical importance.
Property 4. If all weights (frequencies) are divided by some constant number d, then the arithmetic mean will not change, since this reduction will equally affect both the numerator and denominator of the formula for calculating the mean.
Two important consequences follow from this property.
Consequence 1. If all weights are equal, then the calculation of the weighted arithmetic mean can be replaced by the calculation of the simple arithmetic mean.
Consequence 2. The absolute values of frequencies (weights) can be replaced by their specific weights.
Property 5. If all options are divided or multiplied by some constant number d, then the arithmetic mean will decrease or increase by d times.
Property 6. If all options are reduced or increased by a constant number A, then similar changes will occur with the average.
The applied properties of the arithmetic mean can be illustrated by applying the method of calculating the average from the conditional beginning (the method of moments).
Arithmetic mean in the way of moments calculated by the formula:
where A is the middle of any interval (preference is given to the central one);
d is the value of the equal interval, or the largest multiple divisor of the intervals;
m 1 is the moment of the first order.
Moment of the first order is defined as follows:
 .
.
We will illustrate the technique of applying this calculation method using the data of the previous example.
Table 5.6
| Work experience, years | Number of workers | Interval x | |||
| up to 5 | 2,5 | -10 | -2 | -28 | |
| 5-10 | 7,5 | -5 | -1 | -22 | |
| 10-15 | 12,5 | ||||
| 15-20 | 17,5 | +5 | +1 | +25 | |
| 20 and up | 22,5 | +10 | +2 | +22 | |
| Total | X | X | X | -3 |
As can be seen from the calculations given in Table. 5.6 one of their values 12.5 is subtracted from all options, which is equal to zero and serves as a conditional reference point. As a result of dividing the differences by the value of the interval - 5, new variants are obtained.
According to the results of Table. 5.6 we have: ![]() .
.
The result of calculations by the method of moments is similar to the result that was obtained using the main method of calculation by the arithmetic weighted average.
Structural averages
Unlike power-law averages, which are calculated based on the use of all variants of the attribute values, structural averages act as specific values that coincide with well-defined variants of the distribution series. The mode and median characterize the value of the variant occupying a certain position in the ranged variation series.
Fashion is the value of the feature that occurs most often in this population. In the variation series, this will be the variant with the highest frequency.
Finding a Mode in a Discrete Series distribution does not require calculations. By looking at the frequency column, find the highest frequency.
For example, the distribution of workers in an enterprise by qualification is characterized by the data in Table. 5.7.
Table 5.7
The highest frequency in this distribution series is 80, which means that the mode is equal to the fourth digit. Consequently, workers with the fourth category are most often encountered.
If the distribution series is interval, then only the modal interval is set by the highest frequency, and then the mode is already calculated by the formula:
![]() ,
,
where is the lower limit of the modal interval;
is the value of the modal interval;
is the frequency of the modal interval;
is the frequency of the premodal interval;
is the frequency of the postmodal interval.
We calculate the mode according to the data given in Table. 5.8.
Table 5.8
This means that most often enterprises have a profit of 726 million rubles.
The practical application of fashion is limited. They are guided by the value of fashion when determining the most popular sizes of shoes and clothing when planning their production and sale, when studying prices in wholesale and retail markets (the main array method). Mode is used instead of the average when calculating possible reserves of production.
Median corresponds to the variant in the center of the ranked distribution series. This is the value of the feature that divides the entire population into two equal parts.
The position of the median is determined by its number (N).
where is the number of population units. We use the data of the example given in Table. 5.7 to determine the median.
![]() , i.e. the median is equal to the arithmetic mean of the 100th and 110th values of the attribute. Based on the accumulated frequencies, we determine that the 100th and 110th units of the series have a feature value equal to the fourth digit, i.e. the median is the fourth digit.
, i.e. the median is equal to the arithmetic mean of the 100th and 110th values of the attribute. Based on the accumulated frequencies, we determine that the 100th and 110th units of the series have a feature value equal to the fourth digit, i.e. the median is the fourth digit.
The median in the interval series of the distribution is determined in the following order.
1. The accumulated frequencies are calculated for this ranked distribution series.
2. Based on the accumulated frequencies, a median interval is established. It is located where the first cumulative frequency is equal to or greater than half of the population (of all frequencies).
3. The median is calculated by the formula:
 ,
,
where is the lower limit of the median interval;
– interval value;
is the sum of all frequencies;
is the sum of accumulated frequencies preceding the median interval;
is the frequency of the median interval.
Calculate the median according to the table. 5.8.
The first accumulated frequency, which is equal to half of the population 30, means the median is in the range 500-700.
![]()
This means that half of the enterprises make a profit of up to 676 million rubles, and the other half over 676 million rubles.
The median is often used instead of the mean when the population is heterogeneous because it is not influenced by the extreme values of the attribute. The practical application of the median is also related to its minimality property. The absolute sum of deviations of individual values from the median is the smallest value. Therefore, the median is used in calculations when designing the location of objects that will be used by various organizations and individuals.


















